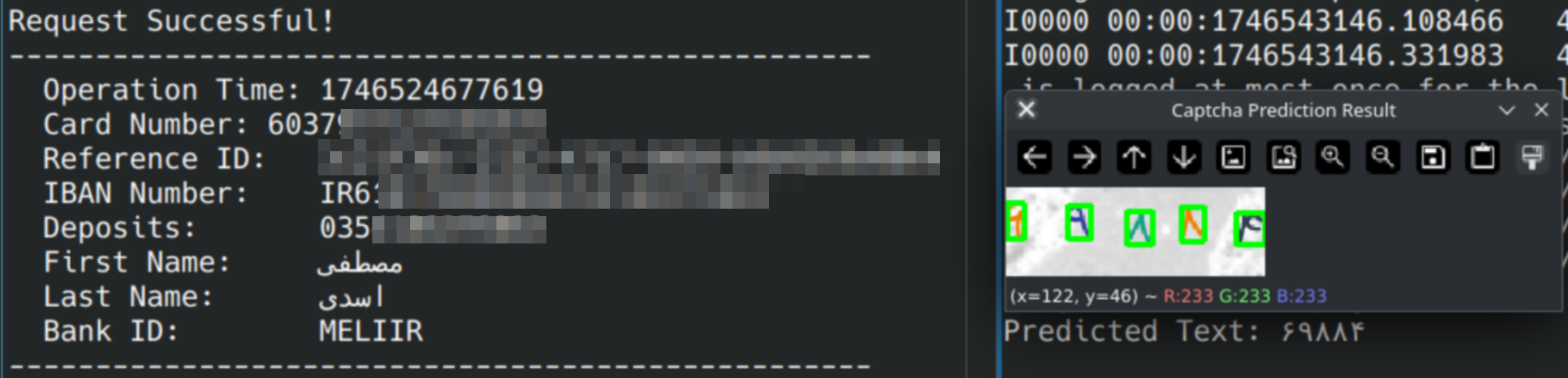
آنچه بود
داستان از آنجا شروع شد که برای انتقال پول از اینترنت بانک حسابهای حقوقی بانک صادرات صرفا میتوان از طریق شماره شبا اقدام کرد (پل یا پایا) و هر بار که شماره کارتی برایم ارسال میشد مجبور بودم یا درخواست کنم که شماره شبا بفرستند یا معمولا از طریق سایتهای خدماتی تبدیل کنم! فرآیندی که برای منِ برنامهنویس مایه تمسخر توسعهدهندگان بانک و بسیار کسلکننده بود! 🐼
این مدت از سایت بسیار خوبی (برای جلوگیری از سوءاستفاده معرفی نمیکنم) که امکان تبدیل شماره کارت به شبا را بصورت رایگان میداد استفاده میکردم ولی هنوز مشکل این فرآیند خستهکننده پابرجا بود؛ از ارسال شماره کارتهای بیفرم و بافاصله و دارای کاراکتر فارسی تا تایپ و تایید کپچا و..
هرچند میدانستم که API تبدیل شماره کارت به شبا در دسترس هست و کار بسیار راحت است ولی از طرفی مدتی بود که میخواستم توسعه یک مدل هوش مصنوعی مبتنی بر تصویر هم تست کنم، این شد که عزم خود را جزم نموده که یک پایان سخت بهتر از سختی بیپایان است!
آنچه مینویسم صرفا اولین تجربه من در توسعه مدل هوش مصنوعی خواندن کپچاست.
سایت مورد نظر یک فرم ساده ورود شماره کارت انگلیسی دارد و یک کپچای ۵ رقمی اعداد فارسی که پس از پست این دو در کنار چند کلید امنیتی دیگر پاسخ را به شما برمیگرداند
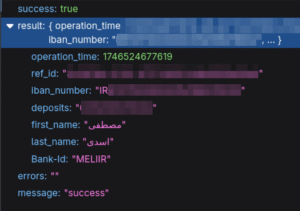

آنچه گذشت
دست به مرورگر شدم و از جمینای و چتجیپیتی کمک گرفتم، کمی چند مدل موجود را دیدم، چند مخزن گیتهاب را خواندم، کمی مستندات openCV و TensorFlow خواندم و نهایتا به این نتیجه رسیدم که من به ۴ بخش کد نیاز دارم:
۱. تولید دیتاست مشابه با اعداد کپچا به تعداد کافی
۲. آموزش مدل یادگیری عمیق بر پایه شبکههای عصبی کانولوشنی (CNN)
۳. پردازش و تشخیص اعداد در تصویر برای ارسال به مدل
۴. دریافت و ارسال دادههای مورد نیاز برای تبدیل شماره کارت به شبا از/به سایت
خب دست به کار شدم و مشابه نمونههای مشابه و توصیههای مستندات یک مدل ۳۰ میلیون پارامتری با آموزش ۱۰۰هزار عکس کپچای رندم ساختم ولی متاسفانه مدل به خوبی اعداد را تشخیص نمیداد، معمولا فقط یک یا دو رقم را تشخیص میداد که همین هم برایم بارقه امید شد!
تلاشهای زیاد برای سوال پرسیدن از هوش مصنوعی و بالا پایین کردن مستندات راه به جایی نبرد که دست به دامان علیِ عزیز شدم که فرمود هرچیزی جدیدش خوبه، رفیق قدیمی!
با راهنماییها و بازبینی علی از دیتاست، مدل و کدها به ۳ اشکال-پیشنهاد رسیدیم:
۱. آموزش مدل برای اعداد تکی بجای یک عدد ۵ رقمی کامل
۲. کم کردن تعداد لایههای مدل و تغییرات در پارامترهای نرخ آموزش که مدل را کوچکتر کرد
۳. ساخت دیتاست بر اساس اعداد تک رقمی سیاهسفید و مدیریت رنگ و نویز در مرحله پردازش
ادامه این فرآیند بدون راهنماییهای دقیق علی واقعا به بنبست میرسید.
آنچه شد
۱. ساخت دیتاست
ساخت دیتاست مشابه نمونهها بخش مهمی از فرآیند بود، نمونه کپچاها چنین تصاویری بودند


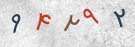
پس از تستهای متفاوت، چندین آموزش ناموفق یا نادقیق به این نتیجه رسیدیم که دیتاست نمونه باید تصاویری باینری شامل یک تک عدد با فونت ایران سنس (بعدتر برای تنوع در تشخیص بین ۲ و ۳ فونت وزیر هم اضافه کردم) با کمی نویز و چرخش باشند، با کمک کتابخانه pillow این چند خط هسته اصلی این کار را انجام میدهند:
for digit in DIGITS:
for i in range(SAMPLES_PER_CLASS):
bg = create_white_background(IMAGE_SIZE)
font = ImageFont.truetype(random_font_path, FONT_SIZE)
draw = ImageDraw.Draw(bg)
text_color = (۰, ۰, ۰)
# write digit in center
try:
bbox = draw.textbbox((۰, ۰), digit, font=font)
text_w, text_h = bbox[۲] - bbox[۰], bbox[۳] - bbox[۱]
text_x = (IMAGE_SIZE[۰] - text_w) // ۲ - bbox[۰]
text_y = (IMAGE_SIZE[۱] - text_h) // ۲ - bbox[۱]
except AttributeError:
continue
draw.text((text_x, text_y), digit, font=font, fill=text_color)
# rotate
angle = random.uniform(-۴۵, ۴۵)
bg = bg.rotate(
angle,
resample=Image.BICUBIC,
expand=False,
fillcolor=(۲۵۵, ۲۵۵, ۲۵۵))
# make it binary
bg = bg.convert("L")
threshold = ۱۲۸
bg = bg.point(lambda p: ۲۵۵ if p < threshold else ۰, "۱")
# add some noise
bg = add_point_noise(bg, noise_level=۰.۰۱)
# save
filename = os.path.join(OUTPUT_DIR, digit, f"{digit}_{i:۰۴}.png")
bg.save(filename)نتیجه این کد، ۱۰ پوشه شامل عکسهای سیاهسفید متنوع از هر عدد فارسی است.
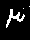
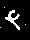
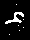
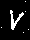
۲. آموزش مدل
مدل که شبکه عصبی کانولوشنی است به بیان ساده تلاش میکند که ویژگیهای مشترک هر عدد مثل لبه، دندانه و منحنی را پس از دیدن نمونههای فراوان یاد بگیرد و بتواند با دستهبندی کردن ویژگیهای هر کلاس تصاویر مشابه آن را بیاید.
با کمک کتابخانههای TensorFlow و Keras دادههای نمونه را بارگیری و به دو بخش داده train و validate تقسیم میکنیم، ابتدا با ایجاد یک لایه Conv2D ویژگیهای اساسی هر تصویر را فیلتر میکنیم سپس پس از چند مرحله نرمالایز و کاهش ابعاد برای حفظ ویژگیهای اصلیتر (BatchNormalization و MaxPooling) نتایج را برداری میکنیم، بعد از این مراحل در لایه پایانی Dense به کمک تابع softmax احتمال تعلق تصویر به یکی از کلاسها (اعداد) را محاسبه میکنیم.
نهایتا مدل را با کمک Adam optimizer که بر اساس جستوجوها بهترین گزینه برای این هدف است (نمیدانم چرا!) با ایده افزایش دقت بین اعداد ۰ تا ۹ آماده و ترین (آموزش) میکنیم.
کد، بخشهای دیگری برای بررسی دقت، ذخیره و اعتبارسنجی مدل در حین آموزش و گزارشگیری از فرآیند نیز دارد که نیاز به توضیح نیست.
هسته اصلی کد ترین مدل این بخش است:
inputs = keras.layers.Input(shape=(IMG_HEIGHT, IMG_WIDTH, ۱))
x = keras.layers.Conv2D(
۳۲, (۳, ۳), activation='relu', padding='same')(inputs)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.MaxPooling2D((۲, ۲))(x)
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(۶۴, activation='relu')(x)
x = keras.layers.Dropout(۰.۵)(x)
outputs = keras.layers.Dense(
NUM_CLASSES, activation='softmax', dtype='float32')(x)
model = keras.models.Model(inputs=inputs, outputs=outputs)
optimizer = keras.optimizers.Adam(learning_rate=۰.۰۰۱)
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(
train_generator,
steps_per_epoch=train_generator.samples // BATCH_SIZE,
validation_data=validation_generator,
validation_steps=validation_generator.samples // BATCH_SIZE,
epochs=EPOCHS,
callbacks=[early_stopping, model_checkpoint]
)
model.save(MODEL_SAVE_PATH)نتایج آموزش
این مدل برای ۱۰۰هزار داده نمونه (هر عدد ۱۰ هزار) شامل ۶۱۵ هزار پارامتر خواهد بود که جزییات هر لایه به شرح زیر است:
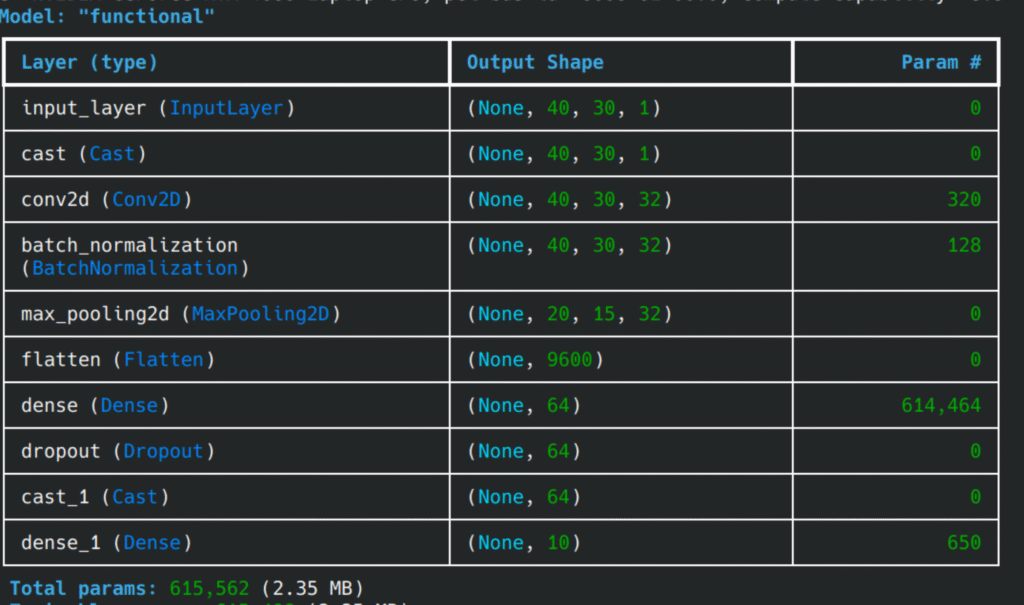
این مدل بعد از ۲۱ ایپوک به دقت تقریبا نزدیک به ۱۰۰ درصد رسید! 😎
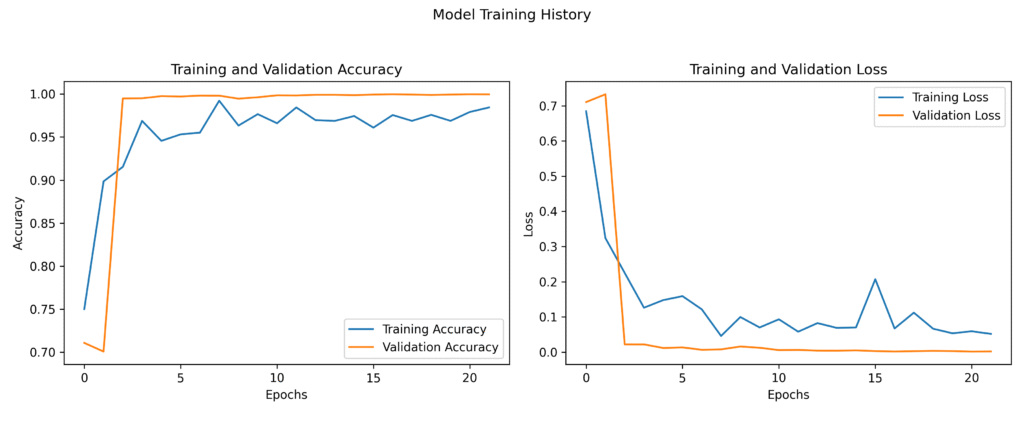
۳. تست مدل
همانطور که در ابتدا گفتم، مدل ما برای تشخیص فریمهای ۳۰ در ۴۰ پیکسلی سیاهسفید شامل یک عدد، آموزش دیده است و حالا برای استفاده نیز باید اعداد در تصویر را بیابیم و در سایز و فرمت مناسب به مدل بدهیم.
به کمک کتابخانه openCV تصویر کپچا را خوانده پس از سیاهسفید کردن، با روش آستانه روشنایی (adaptiveThreshold) قسمتهای پرنورتر که اعداد هستند را از پسزمینه جدا میکنیم سپس با کمک تابع findContours اجزای روشن تصویر (احتمال زیاد اعداد) را یافته و پس از حذف اجزای ریز (احتمالا نویزها) مختصات حضور اعداد را ذخیره و پس از پردازش این ناحیه برای تشخیص (predict) به مدل ارسال میکنیم.
هسته اصلی بخش تست مدل چنین است:
image_bgr = cv2.imread(CAPTCHA_IMAGE_PATH)
image_gray = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY)
thresh = cv2.adaptiveThreshold(
image_gray,
۲۵۵,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY_INV,
۳۱,
۳۰)
contours, hierarchy = cv2.findContours(
thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
digit_bounding_boxes = []
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
min_h, max_h = ۱۵, IMG_HEIGHT_MODEL + ۲۰
min_w, max_w = ۵, IMG_WIDTH_MODEL + ۱۵
if min_h < h < max_h and min_w < w < max_w:
digit_bounding_boxes.append((x, y, w, h))
digit_bounding_boxes.sort(key=lambda item: item[۰])
predicted_captcha = []
for i, (x, y, w, h) in enumerate(digit_bounding_boxes):
pad = ۵
digit_roi = thresh[
max(۰, y-pad):min(thresh.shape[۰], y+h+pad),
max(۰, x-pad):min(thresh.shape[۱], x+w+pad)]
if digit_roi.size == ۰:
predicted_captcha.append('X')
continue
resized_digit = cv2.resize(
digit_roi, (IMG_WIDTH_MODEL, IMG_HEIGHT_MODEL))
processed_digit = resized_digit.astype('float32') / ۲۵۵.۰
processed_digit = np.expand_dims(processed_digit, axis=-۱)
processed_digit = np.expand_dims(processed_digit, axis=۰)
# predict the digit
prediction = model.predict(processed_digit)
predicted_class_index = np.argmax(prediction, axis=۱)[۰]
predicted_captcha.append(int(predicted_class_index))نتایج تست
اینجا همان جایی بود که سرشار از حس رضایت شدم! 😍
مدل با سرعت و دقت خوبی، نمونههای واقعی کپچا را تشخیص میدهد، شاید هنوز کمی تغییر در پارامترهای adaptiveThreshold میتواند فرآیند را بهبود دهد.
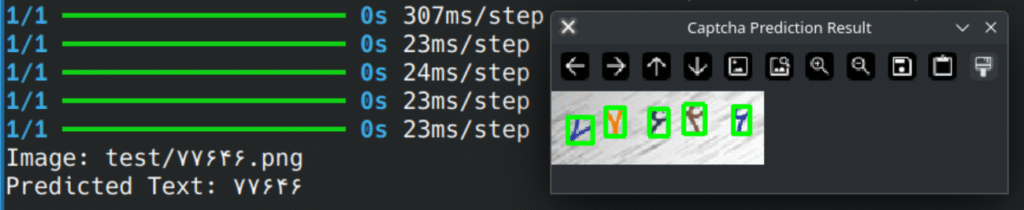
۴. استفاده از مدل
بالاخره پس از ساختن این کوه مدل از کاهِ مساله، وقت باز کردن گره با دندان برای نفسی راحت کشیدن است، به کمک کتابخانههای Requests و BeautifulSoup کپچا و کلیدهای امنیتی را دریافت میکنیم و پس از ارسال تصویر به مدل و تشخیص آن، درخواست را برای سایت میفرستیم، نتیجه به قول اجنبیها ستیس فاینینگ است! 😌
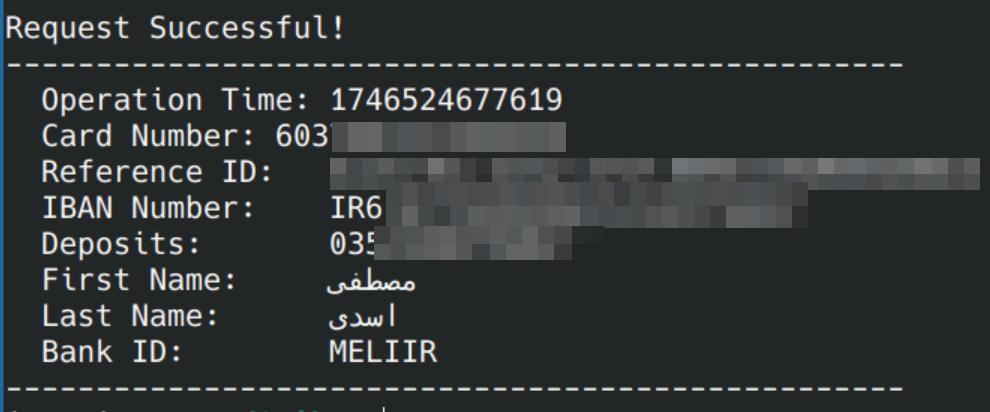
پینوشت
۱. با تشکر از علی، جمینای و چتجیپیتی.
۲. هدف من از انتشار این نوشته به اشتراک گذاشتن قدمهای ابتدایی آموختن و آزمودن بود.
۳. برای تشکر و احترام به خدمات عامالمنفعه، نام سایت را افشا نمیکنم.
۴. کدها و مدل ترین شده را در گیتهاب میتوانید با لایسنس GPL ببینید و بخوانید و استفاده کنید.
۵. مراقب کپچاهای ساده و دادههای مهم خود باشید!
دیدگاهتان را بنویسید